
Few days ago, we released a preprint1 showing evidence that symbol grounding can emerge in language models. 1 The Mechanistic Emergence of Symbol Grounding in Language Models (Wu*, Ma* and Luo* et al., 2025) The dust of release has not yet settled, and already a friend, after reading the manuscript, messaged me (Martin):
"I wouldn't have thought to link these things. What made you do it?"
That question stayed with us, as it exposed a quiet truth about research: we too often present it as a polished surface or a linear arc from premise to conclusion, when in practice it unfolds as a cartography of detours. What looks, in retrospect, like a straight line was, in fact, a constellation of hunches, failed starts, fragile insights, and long hours spent staring at phenomena no one else thought worth staring at.
The ethos of open-notebook science has long resonated with us. It is a quiet belief that knowledge does not emerge solely from final proofs or polished figures, but also from the raw material of inquiry: half-formed ideas, imperfect setups, unpublished (even negative2) results, and the many intermediate steps that usually remain unseen. 2 Illuminating 'the ugly side of science': fresh incentives for reporting negative results (Brazil, 2024)
Interpretability research moves forward through curious observations and moments when we choose to look closer instead of turning away. This blog is not only about what we found; it is about how we came to see, shape, and articulate those findings. What follows keeps the non-linear nature of the work intact. Results that shaped the paper, results that refused to fall into place, and results that were simply too strange to overlook are all included here, with only the most obvious bugs set aside.
Observations
Over the past few years, (large) vision-language models (VLMs) have come to be seen as general-purpose problem solvers, capable of integrating text, images, and other perceptual inputs. We see clear evidence that semantic correspondences emerge inside these models: language tokens align with visual entities and structures, enabling zero-shot localization, segmentation, and cross-modal matching. 3 GROUNDHOG: Grounding Large Language Models to Holistic Segmentation (Zhang et al., 2024)
Recent studies describe this phenomenon as "grounding" emerging without explicit supervision, based on the observation that language tokens naturally map onto visual regions and structures during large-scale training. Below are a few representative examples:
| Paper | What's Observed | Operational Definition of Grounding | Operational Definition of Emergence |
|---|---|---|---|
| Bousselham et al. (2024)4 | Self-attention patterns cluster visual tokens into object-like groups aligned with textual prompts. | Text-aligned object localization and segmentation obtained directly from pretrained attention structure. | Localization emerges without fine-tuning or additional objectives, as a property of pretrained attention. |
| Cao et al. (2025)5 | Attention maps produce pixel-level masks through an attend-and-segment procedure. | Alignment between language spans and pixel regions derived from internal attention. | Masking ability appears spontaneously during large-scale training without grounding supervision. |
| Schnaus et al. (2025)6 | Independently trained language and vision embedding spaces align through geometric matching. | Cross-modal correspondence between linguistic and visual representations without paired data. | Alignment emerges from structural convergence in embedding geometry, not explicit supervision. |
These observations are genuinely interesting: they suggest that the capacity to align language symbols with perceptual structure may arise spontaneously during large-scale training. Yet they are not examples of symbol grounding in the classical sense of Harnad (1990)7. 7 The Symbol Grounding Problem (Harnad, 1990) While these studies provide preliminary evidence of grounding-like behavior, their operational definitions of grounding and emergence are limited. Grounding is framed primarily through spatial correlations or geometric correspondences, and emergence is defined descriptively as the presence of such patterns in a trained model rather than a principled account of when, how, or why they arise during learning. Thus one can only conclude that what emerges in these settings is evidence of statistical correlations, rather than demonstrable causal anchoring of symbols to referents in the world. Any stronger claim about grounding would extend beyond what the evidence supports.
This gap between emergent correlations and symbol grounding is precisely where our curiosity begins. Rather than studying grounding only as a static property of a finished model, we turn our attention to the learning trajectory itself: when does grounding emerge, how does it specialize, and what mechanisms give rise to it. By tracing these dynamics with causal interventions and controlled comparisons, we aim to move from observing alignment to understanding its origin.
Minimal Testbed
The first step in our investigation is to establish clear (i) conceptual and (ii) operational definitions, together with (iii) a minimal testbed that allows us to formalize the problem in a controlled setting.
- We treat emergence conceptually as a capacity or structure that arises spontaneously as a byproduct of large-scale optimization on a proxy task, rather than being explicitly imposed through supervision or inductive biases. Operationally, emergence should not be inferred solely from the final trained model. Instead, it must be probed throughout the entire training trajectory, which requires either retraining our language models from scratch or leveraging open-weight models with accessible intermediate checkpoints, such as Pythia or Olmo.
-
We define grounding conceptually as the process of mapping a primary data source
Xto an external resourceYthat serves as its ground.8 8 Learning Language through Grounding (Shi et al., 2025) In the VLM setting, symbol grounding will correspond to the question of how discrete linguistic symbols (tokens) acquire meaning through their mapping to the visual perception.
To minimize confounds introduced by the visual perception system and study symbol grounding in a controlled setting, we construct a minimal testbed that satisfies two key requirements: (i) the dataset should be as simple as possible while still capturing essential aspects of realistic language model training; and (ii) the task should have a "true" grounded solution, meaning that certain tokens explicitly refer to external entities or events. This makes it possible to probe whether and how such links emerge during learning.
A natural candidate corpora for this purpose is the Child Language Data Exchange System (CHILDES9), 9 The CHILDES Project: Tools for Analyzing Talk (MacWhinney, 2000) which provides speech transcriptions paired with environmental annotations. This offers a structured yet ecologically meaningful context for examining grounding in language models. Below is an example corpus snippet:
*CHI: My favorite animal is the horse.
%act: painted a picture of a horse
The above utterance from a child (CHI) is paired with a non-verbal description of their actions (%act),
which essentially means that the child was painting a picture of a horse while saying "My favorite animal is the horse."
We thus design a minimal testbed with a custom word-level tokenizer, in which every lexical item is represented in
two corresponding forms. One token appears in non-verbal descriptions
(for example, a horse in the scene description), and another appears in utterances
(for example, horse in speech).
We refer to these as environmental tokens (<ENV>) and linguistic tokens (<LAN>), respectively.
We process the ENG-US and ENG-UK subsets of CHILDES to construct our training corpus.
The previous example can be rewritten in this format as:
<CHI> painted<ENV> a<ENV> picture<ENV> of<ENV> a<ENV> horse<ENV>
<CHI> My<LAN> favorite<LAN> animal<LAN> is<LAN> the<LAN> horse<LAN>
It's worth noting that in this example,
horse<ENV> and
horse<LAN> are converted in two completely different indices by the word-level tokenizer,
and thereby getting rid of superficial form-level connections between them.
Model training follows the standard causal language modeling objective with a whole-word tokenizer. Our primary model architectures include a Causal Transformer in the style of GPT-2, a Unidirectional LSTM, and a State-Space Model (Mamba-2). All experiments are repeated with 5 random seeds, randomizing both model initialization and corpus shuffle order.
Behavioral Evidence
The first step is to confirm this phenomenon of emergence is robust and significant.
Drawing inspration from priming in psychology,
we test the conditional probability of a linguistic token (<LAN>) under two situations.
Take book<LAN> as the target word:
- Match: The corresponding
<ENV>token is presented in the context. - Mismatch: The corresponding
<ENV>token is not presented in the context.
book<ENV> <CHI> I<LAN> love<LAN> reading<LAN> ______,
toy<ENV> <CHI> I<LAN> love<LAN> reading<LAN> ______,
For fair comparison, these two conditions should be minimally different,
so we construct mismatched context with replacing the corresponding <ENV> token with others.
If the conditional probability of the target <LAN> token in the match situation is significantly higher than that in the mismatch case,
we can claim there is reliable behavioral evidence of grounding (still not necessarily symbol grounding yet).
At this stage, two limitations of our initial formulation became clear.
- The linguistic template itself introduced semantic bias: the word reading strongly implies book, making the match condition artificially easier and the mismatch (e.g., toy) linguistically implausible. To avoid such bias, we decided to replace the original template with semantically lighter constructions that do not presuppose specific referents.
-
We already plan to examine attention patterns, but language models tend to
disproportionately focus on the first token in the sequence, creating an
attention sink that can mask more subtle grounding dynamics.10
10
Why do LLMs attend to the first token? (Barbero et al., 2025)
This raises an important ambiguity: we cannot immediately tell whether the
<ENV>token receives more attention because models naturally favor early positions, or because it genuinely serves as the ground for the linguistic form to be predicted.
To address this, we designed more complex environmental contexts and semantically neutral linguistic templates, ensuring that observed differences reflect genuine grounding behavior rather than artifacts of template choice or attention distribution. An example of these new templates is as follows:
<CHI> asked<ENV> for<ENV> a<ENV> new<ENV> book<ENV>
<CHI> I<LAN> love<LAN> this<LAN> ______,
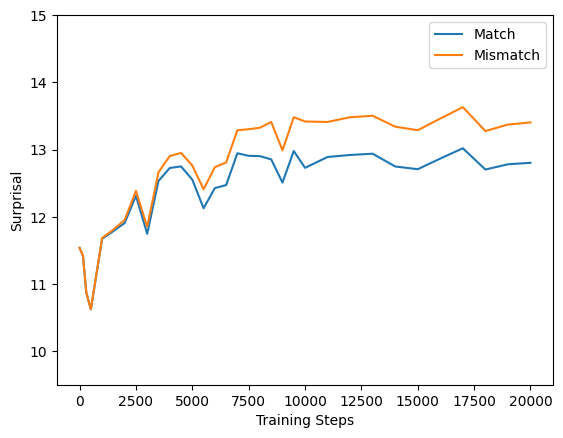
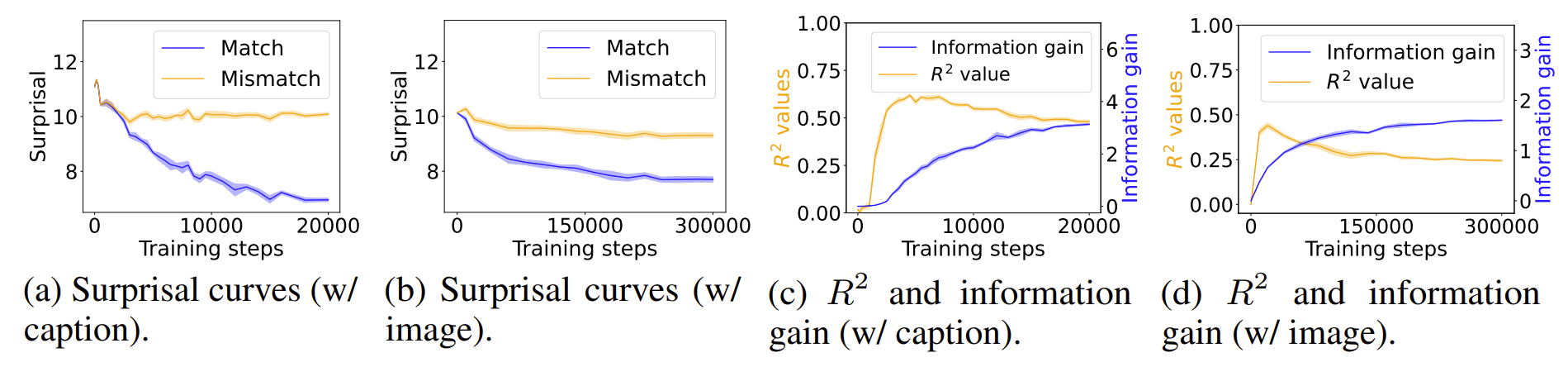
For clarity, we plot the surprisal, defined as the negative log probability of the target token conditioned on context.
We also attempted to extend our study to hybrid architectures that combine Transformer and Mamba-2 layers. Specifically, we experimented with 12-layer hybrid models in which either layers 4-7 or all even-numbered layers were replaced with Mamba-2, while the remaining layers retained the Transformer structure. Interestingly, we still observed consistent grounding behaviors under these configurations. However, we soon realized that a systematic investigation of hybrid architectures would require addressing many design considerations.11 11 A Systematic Analysis of Hybrid Linear Attention (Wang* and Zhu* et al., 2025) Given the scope of current research questions, we decided to omit these results from the main paper and include them here in this blog to motivate future work.
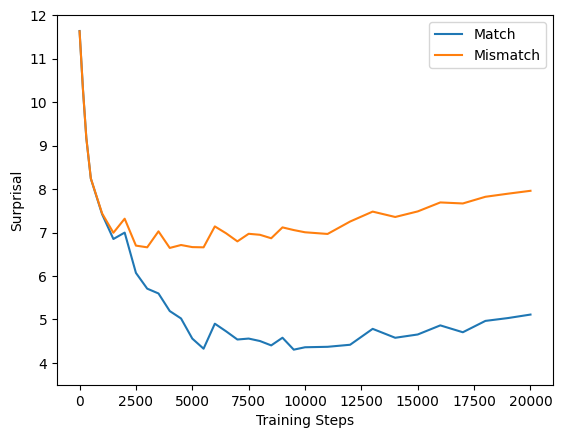
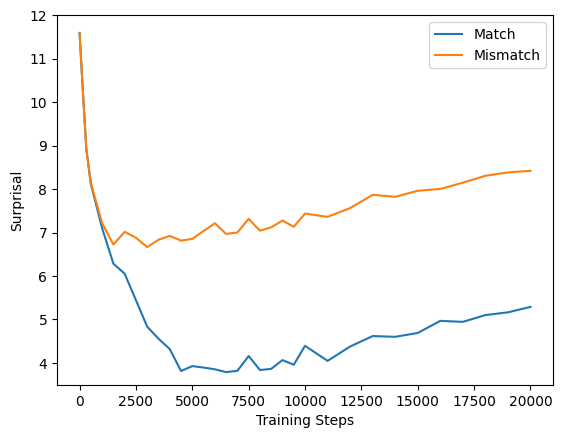
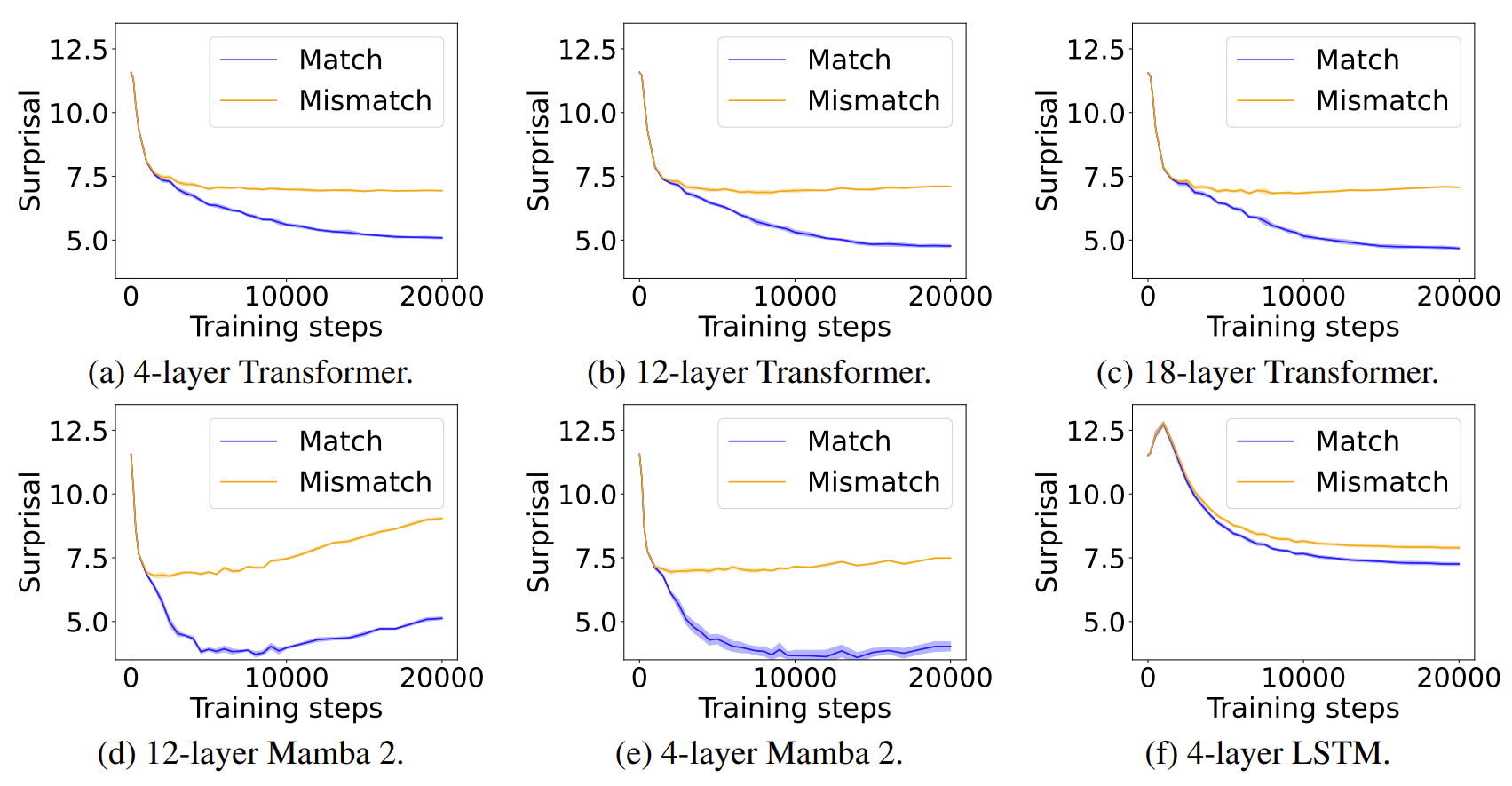
As shown above, all models show clear separation between match and mismatch conditions. We observed two unexpected behaviors during this phase of experimentation:
- Mamba-2 exhibits mild overfitting effects toward the end of training. This behavior can likely be explained by existing work12 on state-space models, 12 Revealing and Mitigating the Local Pattern Shortcuts of Mamba (You* and Tang* et al., 2025) and it does not undermine the main conclusions of our study.
- Transformers and Mamba-2 have much clearer separation than LSTM. One might simply attribute this to the higher capacity of these architectures, but it also raises some concerns about what this behavioral finding truly reflects.
One simple explanation could make these results trivial:
the match advantage might come from frequent co-occurrence between <LAN> and <ENV> tokens.
In that case, the models may have memorized surface-level token statistics rather than learning a genuine mapping.
To test this hypothesis, we start with a data ablation experiment on a 12-layer Transformer.
We define co-occurrence between corresponding <ENV> and <LAN> tokens
when they appear within the same context window (512-token training chunk).
In the CHILDES corpus, roughly one-third of the data contains such co-occurring pairs.
We retrain models after randomly removing different proportions of
these co-occurring chunks from the training data. The results are as follows:
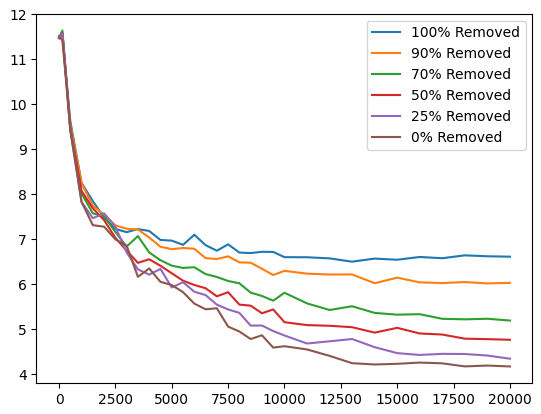
As expected, increasing the amount of co-occurring data enlarges the gap between match and mismatch conditions. However, even when all co-occurring data are removed, a noticeable gap remains. This indicates that language models can still learn to associate words with their grounds in the absence of explicit co-occurrence. In other words, the observed performance gain cannot be explained by surface-level co-occurrence statistics alone.
Fortunately, statistical toolkits offer an easy way to quantify if it's indeed the case.
We can fit a linear regression between the average surprisal difference of a target <LAN> token (which, from an information theoretic perspective, could be also explained as information gain)
and the cumulative co-occurrence, quantified by the number of examples where both
<LAN> and <ENV> are present.
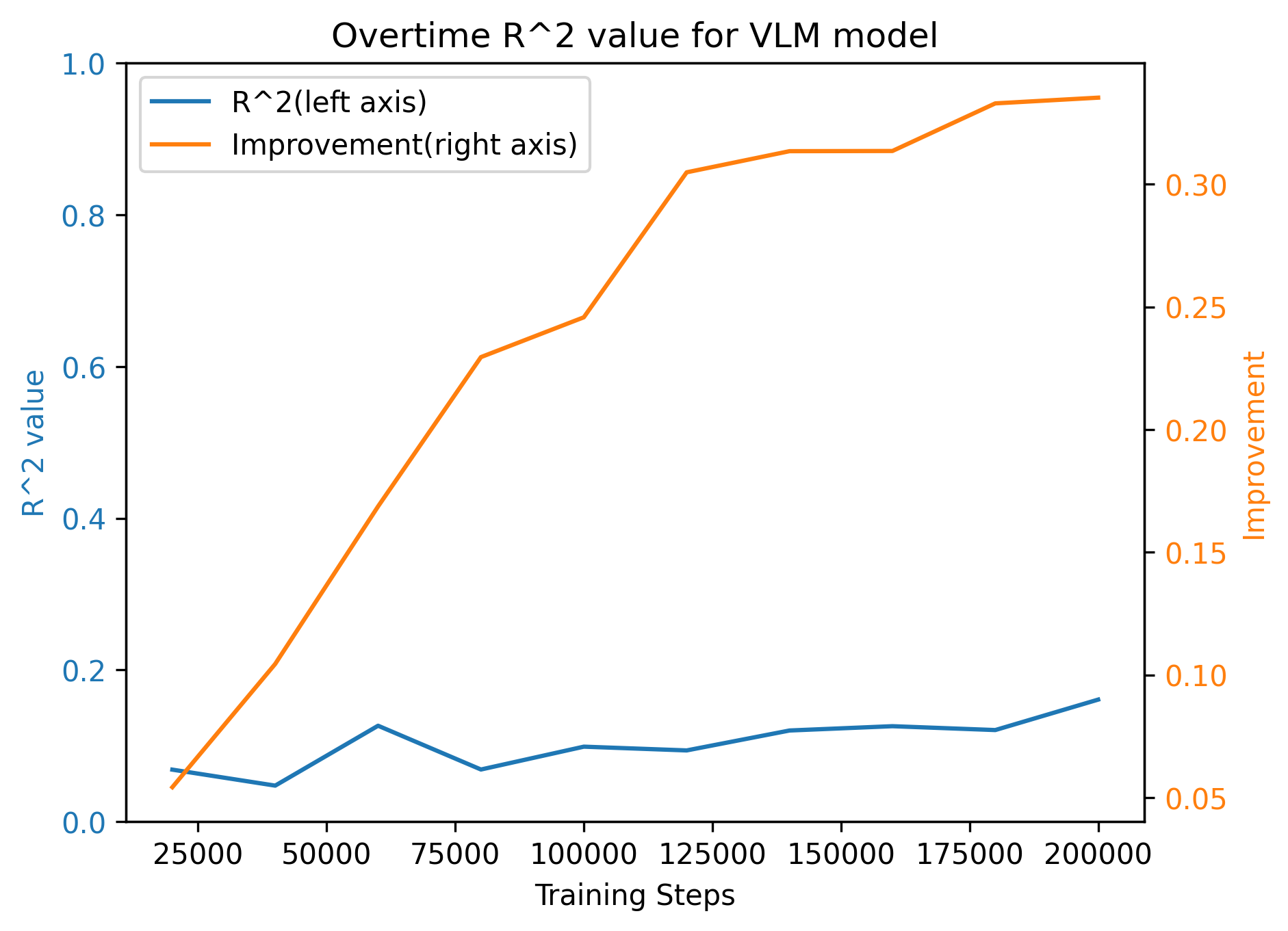
The R2 value of this linear regresion over time shows how well the co-occurrence predicts the information gain.
If the information gain simply comes from co-occurrence, we should see a strictly increasing R2 over time.
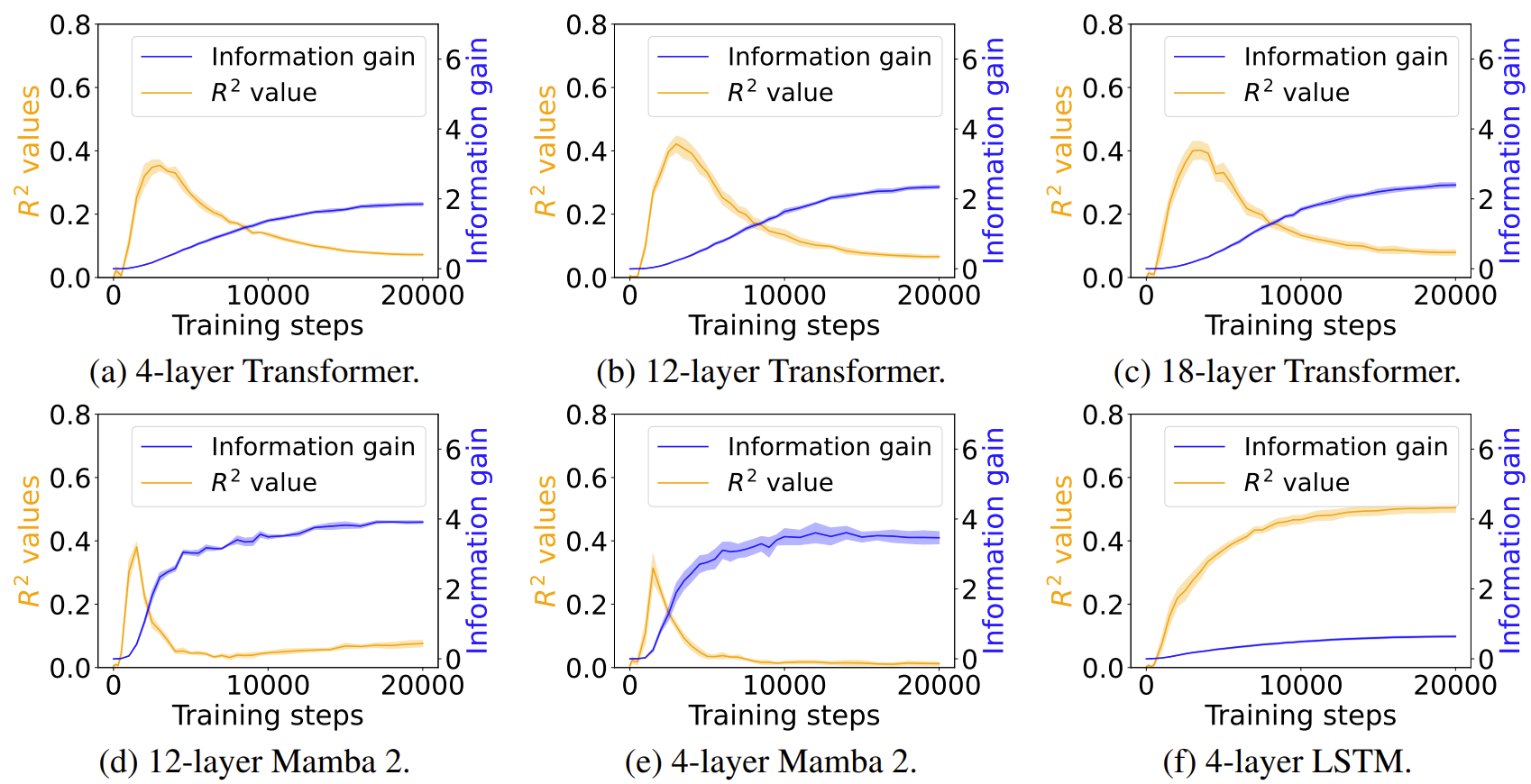
We show the R2 values (orange) alongside the grounding information gain (blue) for different model architectures.
In both the Transformer and Mamba-2, R2 rises sharply during the early training steps but then declines,
even as grounding information gain continues to increase.
This pattern suggests that grounding in these architectures cannot be fully explained by co-occurrence statistics.
Models initially rely on surface regularities but later improvements reflect more complex, learned representations.
In contrast, LSTM shows steadily increasing R2 but little growth in grounding information gain,
indicating that it encodes co-occurrence but lacks the architectural capacity to convert it into predictive grounding.
As a bonus analysis, we flipped the template to test the reverse direction:
given linguistic conditioning, can the model predict the corresponding <ENV> token?
We didn't expect a satisfying performance as the model was never trained in this direction.
<LAN>-to-<ENV> Surprisal Results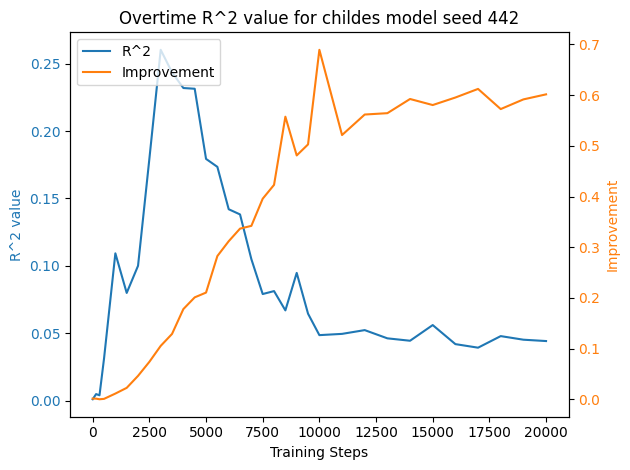
<LAN>-to-<ENV> R2 Results
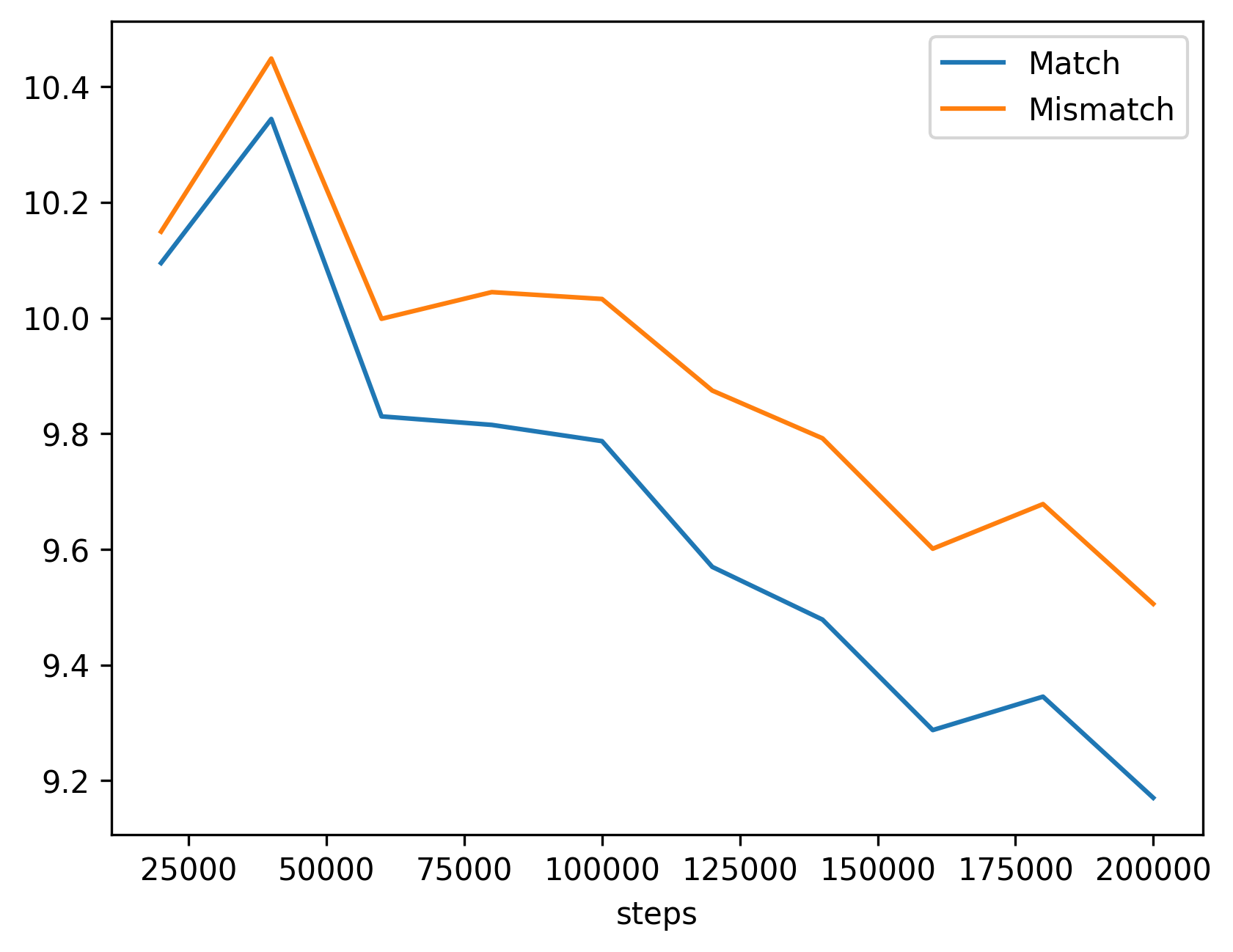
We observed that surprisal for both match and mismatch conditions increases steadily as training progresses,
yet the match group consistently maintains lower surprisal than the mismatch group.
Furthermore, the R2 trend mirrors our previous findings.
This (very weakly) suggests that the model might internalizes a bidirectional mapping between linguistic and environmental tokens
even without explicit training in the reverse direction, reflecting a more general underlying grounding mechanism
rather than a task-specific artifact.
This is not discussed in the paper but included here to simulate possible future discussions and open questions.
Mechanistic Evidence
Taking a closer look at our task setup, we see some similarity between ours and that in Wang et al. (2023).13
In Wang et al. (2023), they study in-context classification settings, and find label words serve as "anchors" that collects information from previous tokens by looking at the information flow.
13
Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning (Wang et al., 2023)
In our setup, if we view the <ENV> tokens as the anchors, we can analyze how they facilitate information flow and grounding in a similar manner.
We hypothesize that, during prediction, salient information flows from the <ENV> tokens into the token immediately preceding the target <LAN> to facilitate the linguistic token prediction.
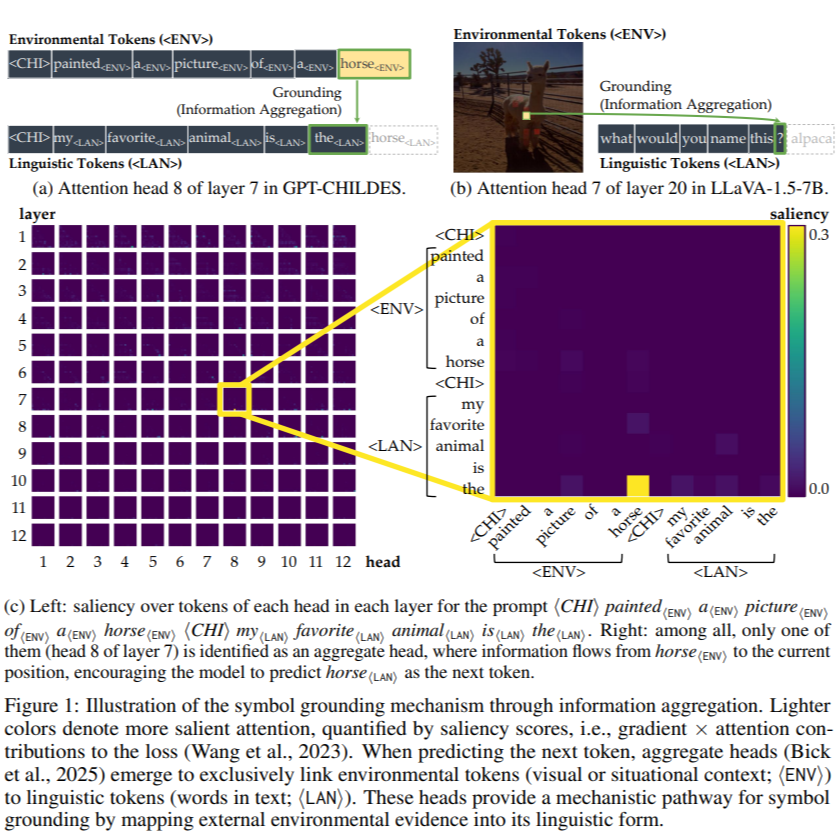
Following Wang et al. (2023), the information flow (i.e., saliency) matrix at Layer $\ell$ and Head $h$ is defined as: $I_{\ell, h} = \frac{\partial L}{\partial A_{\ell, h}} \odot A_{\ell, h}$, where $L$ is the loss function, $A_{\ell, h}$ is the attention matrix at Layer $\ell$ and Head $h$, and $\odot$ denotes element-wise multiplication. The over saliency score from token $i$ to token $j$ at Layer $\ell$ is then computed by aggregating the information flow across all heads:
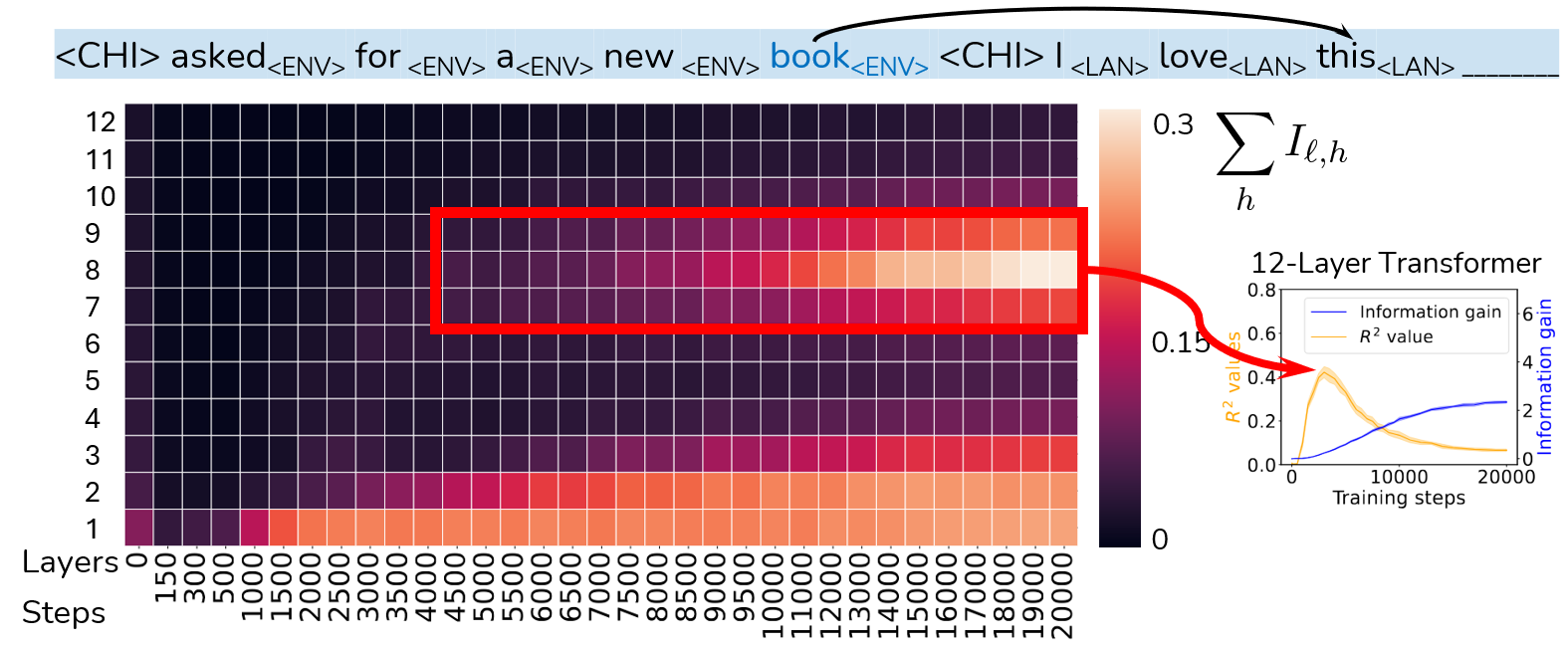
We analyze a 12-Layer Transformer.
As we see above, the saliency at middle layers (Layers 7-9) starts to increase at around 4,500 training steps,
exactly where the R2 (between grounding information gain and co-occurrence) starts to drop in the previous analysis!
If they two are indeed connected, this is evidence suggesting that some mechanisms in the middle layers facilitate grounding beyond co-occurrence statistics.
If the attention mechanism reveals where information flows, then the hidden representations capture what information is being encoded and transformed along the layers.
Our next analysis is from the tuned lens (Belrose et al., 2023),14 which aims at translating model internals to human understandable text.
14
Eliciting Latent Predictions from Transformers with the Tuned Lens (Belrose et al., 2023)
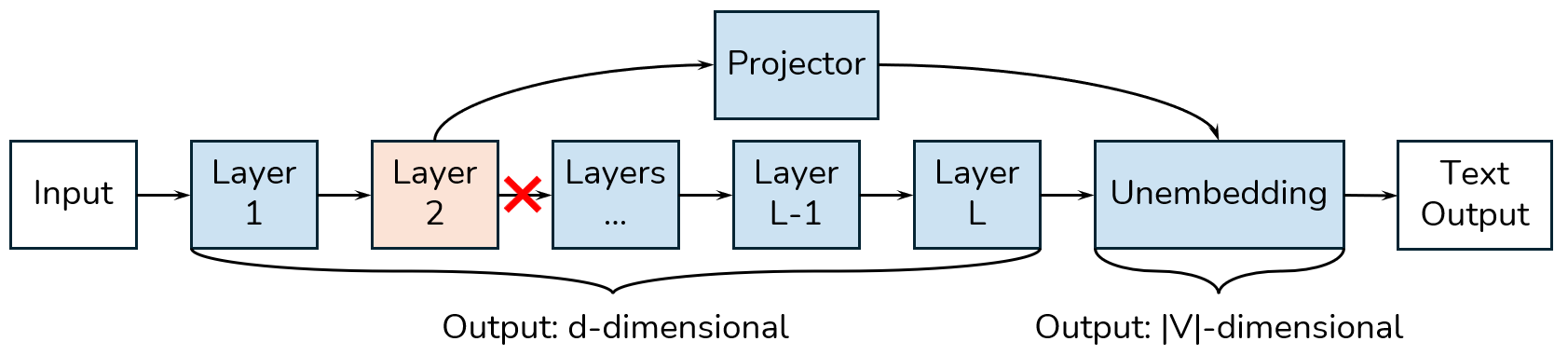
A tuned lens is a trained linear projection layer that maps the hidden states at each layer to the vocabulary space.
We train a tuned lens for each layer at different training steps, and analyze how the surprisal of the target <LAN> token changes over training.
Resonating with the above findings, the tuned lens analysis also highlights the middle layers (Layers 7-9) as critical for grounding. At about 10K to 20K steps, we see a significant drop in surprisal at these layers.
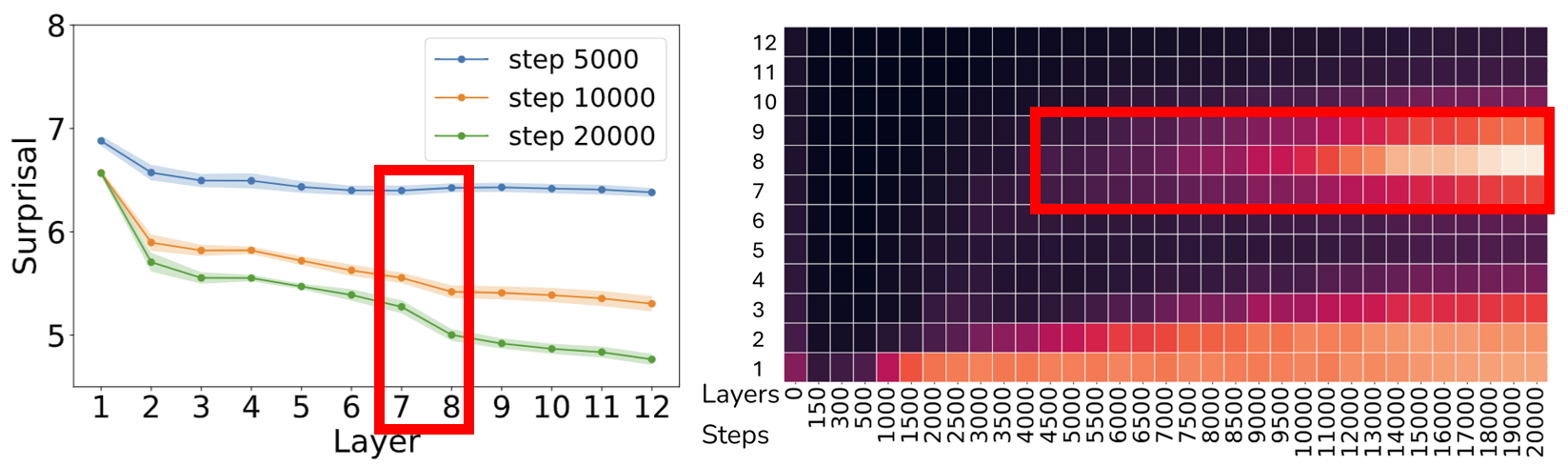
<LAN> token in match conditionTaking all these evidence together, we hypothesize that there are some internal mechanism in the middle layers after 5K steps that implement grounding beyond co-occurrence statistics.
To make our hypothesis more concrete, we examine the saliency of attention heads by plotting them directly. We visualize all attention heads across layers in a grid: each row corresponds to a layer (from top to bottom, layers 1 to 12), and each column represents a head. All values are normalized per head, so we focus first on the behavior of each head individually rather than directly comparing their absolute strengths. This allows us to identify where and when specific heads might specialize in grounding, without the confound of global scale differences across heads.


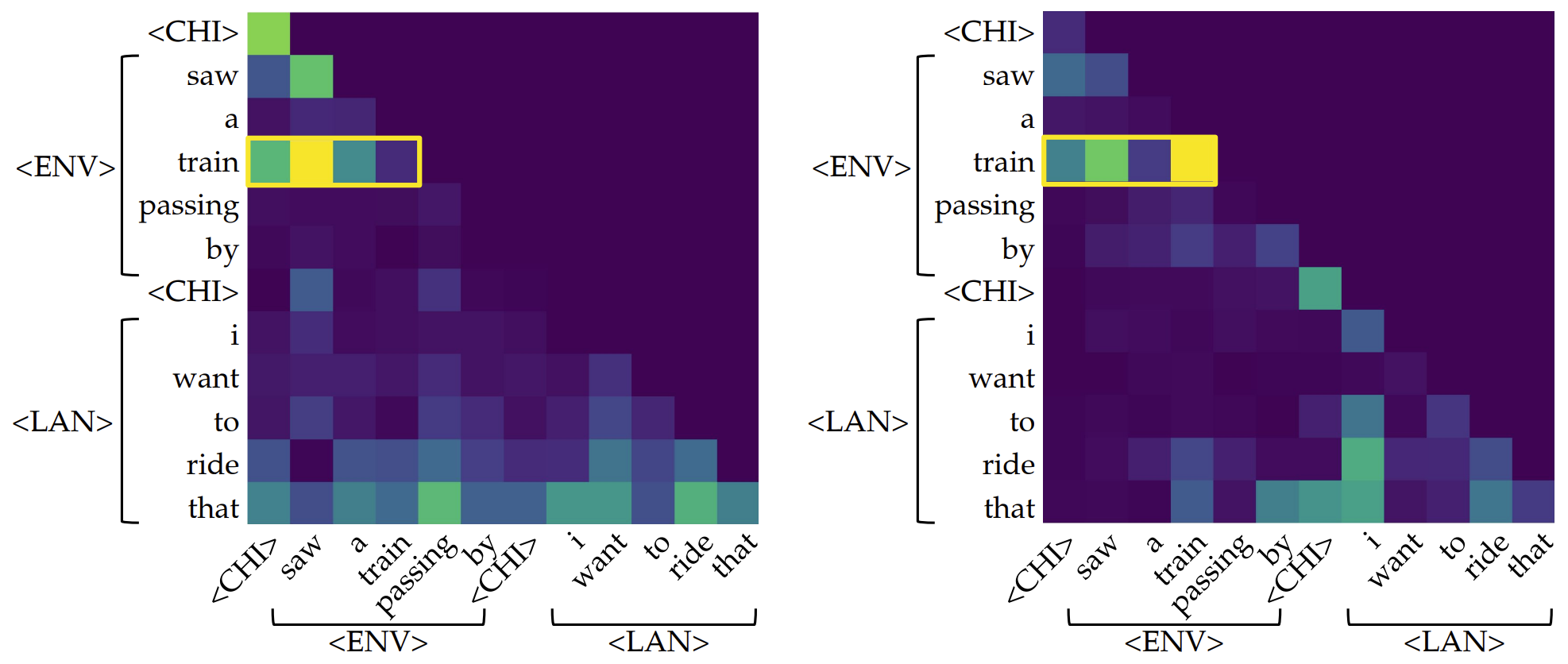
As shown above, there are a few heads that captures our attention. Some of them (mostly in layers 1-4) are almost a horizontal strip, indicating information from all previous tokens flows into one position, whereas others (mostly in layers 7-9) are a single salient dot, indicating that the head is simply transferring information from one specific token to another. This resonates with the findings of Bick et al. (2025),15 where they argue such gather (horizontal strip) and aggregate (single dot) attention patterns are crucial for in-context learning. 15 Understanding the Skill Gap in Recurrent Language Models: The Role of the Gather-and-Aggregate Mechanism (Bick et al., 2025)
In our setting, typical gather heads look like these:
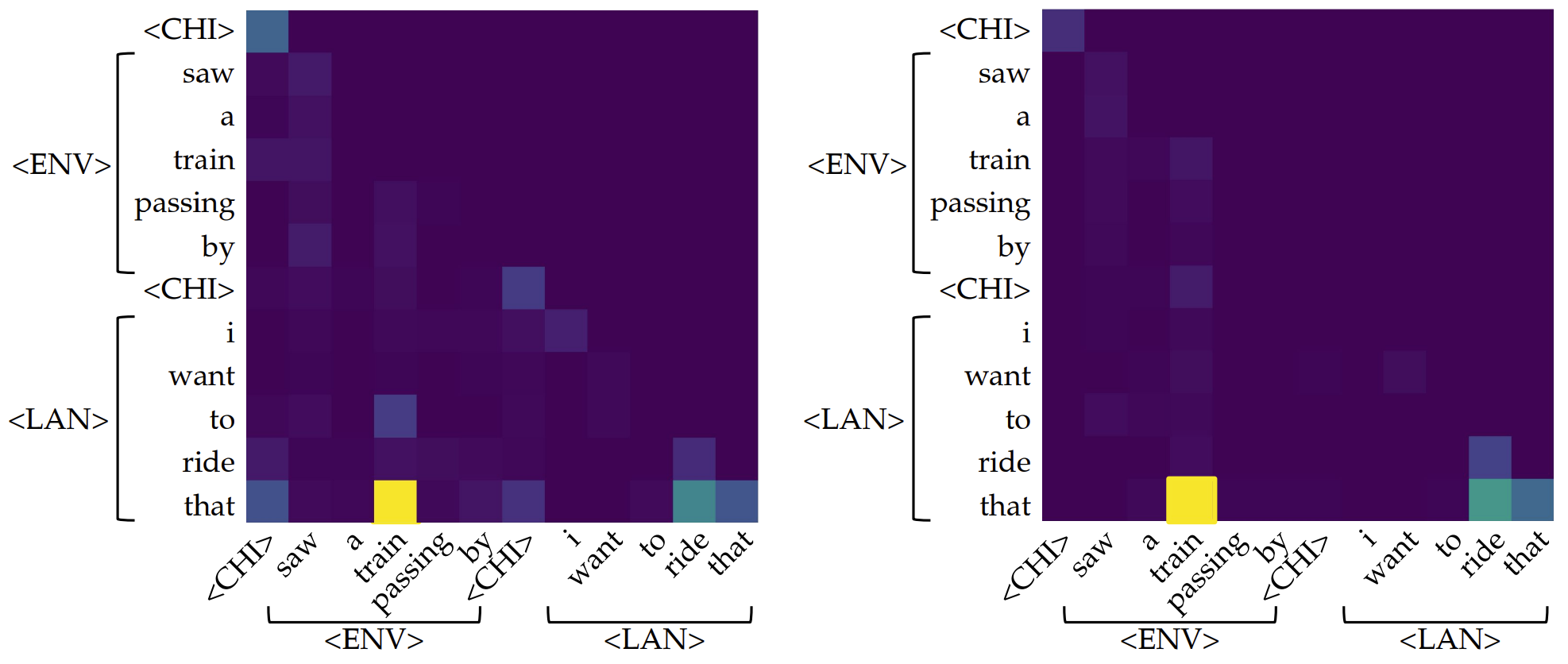
And typical aggregate heads look like these:
We now specifically hypothesize that the gather-and-aggregate mechanism plays a crucial role in enabling symbol grounding, and verify this hypothesis through causal interventions. We detect gather-and-aggregate heads by searching for attention heads that exhibit the following two properties:
- Gather property: The strip at certain position occupies at least 30% of the total saliency mass of the head.
- Aggregate property: A single dot in the head occupies at least 30% of the total saliency mass of the head.
After identifying the set of gather and aggregate heads for each context in the final model, we conduct an over-time analysis to measure how their relative contributions evolve during training. Specifically, we calculate the proportion of saliency attributed to these heads compared to the total saliency across all heads. This allows us to track when grounding-related mechanisms become active and how their influence changes over the course of learning.
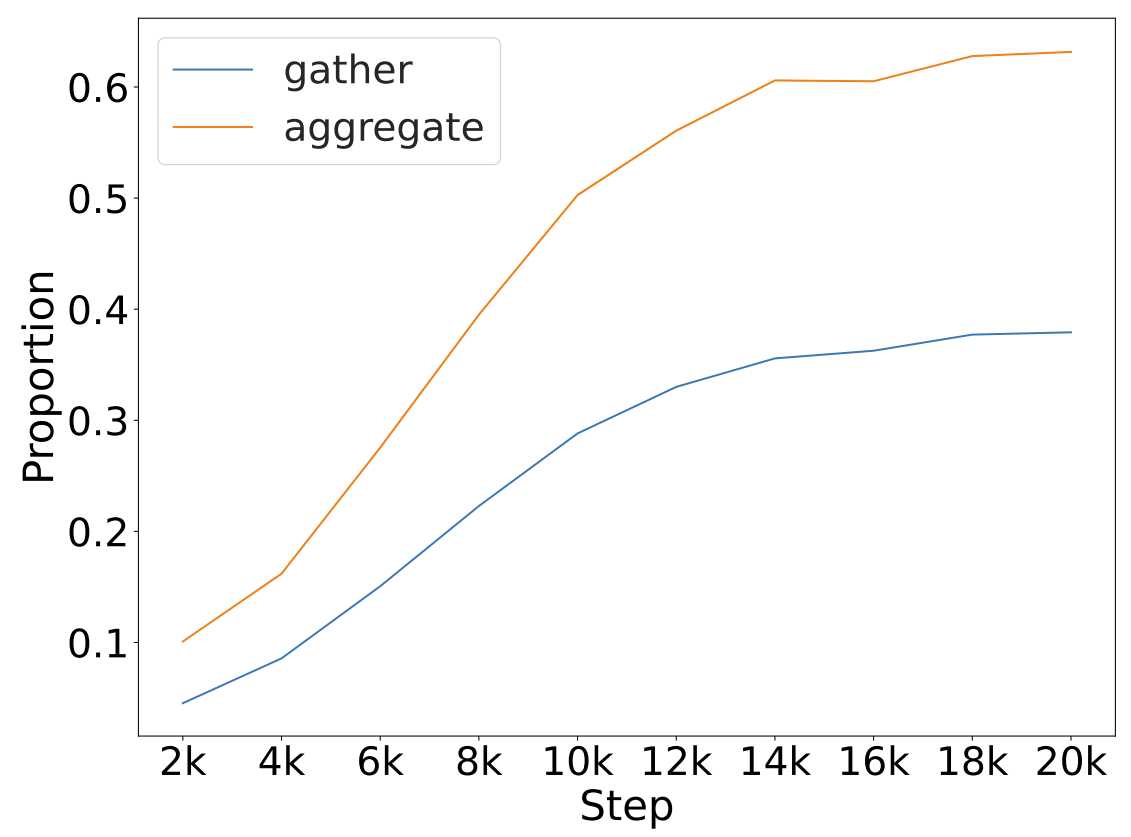
By zeroing-out these heads during inference and comparing to zeroing-out random heads that do not satisfy these properties, we can test if these heads are indeed crucial for grounding. We perform this causal intervention experiments on the identified gather and aggregate heads across training checkpoints. Avg. Count refers to the average number of heads of each type across inference runs, and Avg. Layer indicates the average layer index at which they appear. Interv. Sps. reports surprisal after zeroing out the identified heads, while Ctrl. Sps. reports surprisal after zeroing out an equal number of randomly selected heads. Original refers to baseline surprisal without any intervention. *** indicates a significant difference (p < 0.001), where the intervention surprisal is higher than in the corresponding control experiment.
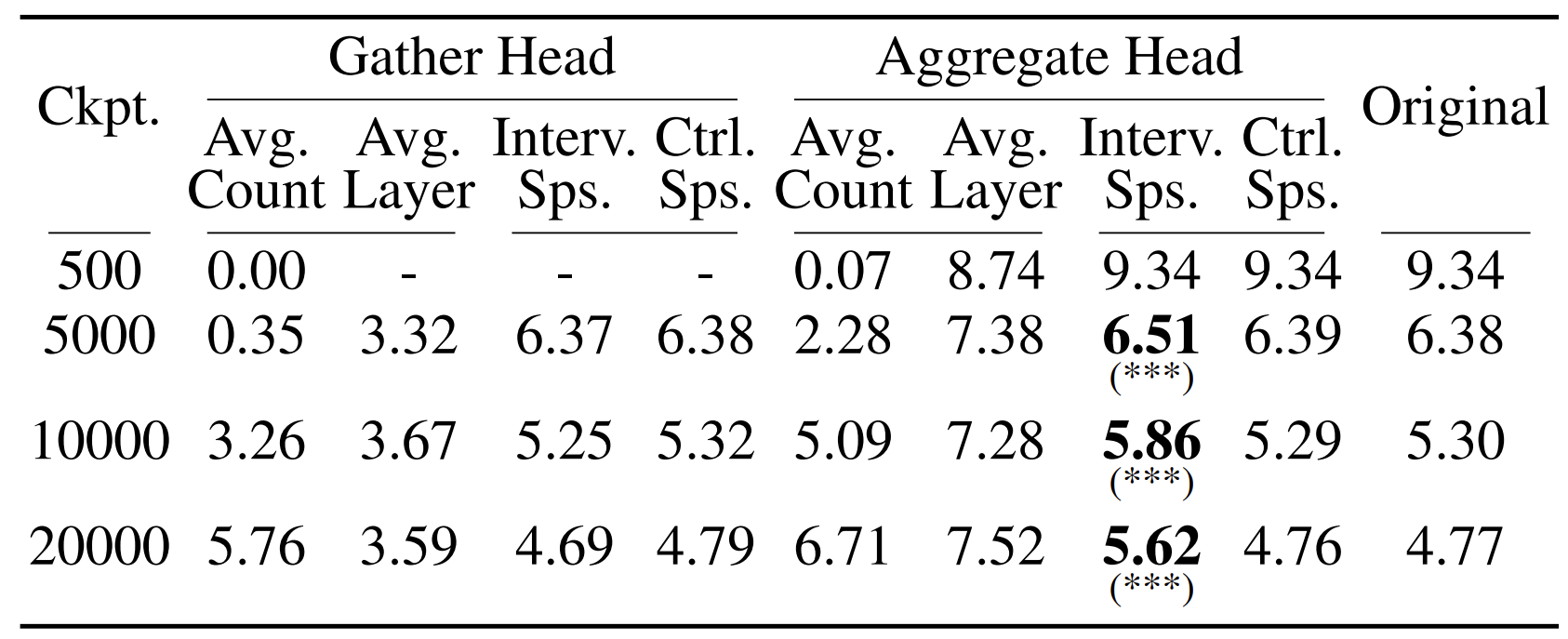
Results above show that only aggregate heads have significant causal effect on grounding performance, partially confirming our hypothesis.
In fact, when we normalize all attention values per model rather than per head, we observe that aggregate heads are substantially more salient than gather heads. In many cases, only one or a few aggregate heads stand out prominently. An example illustrating this pattern is shown below.
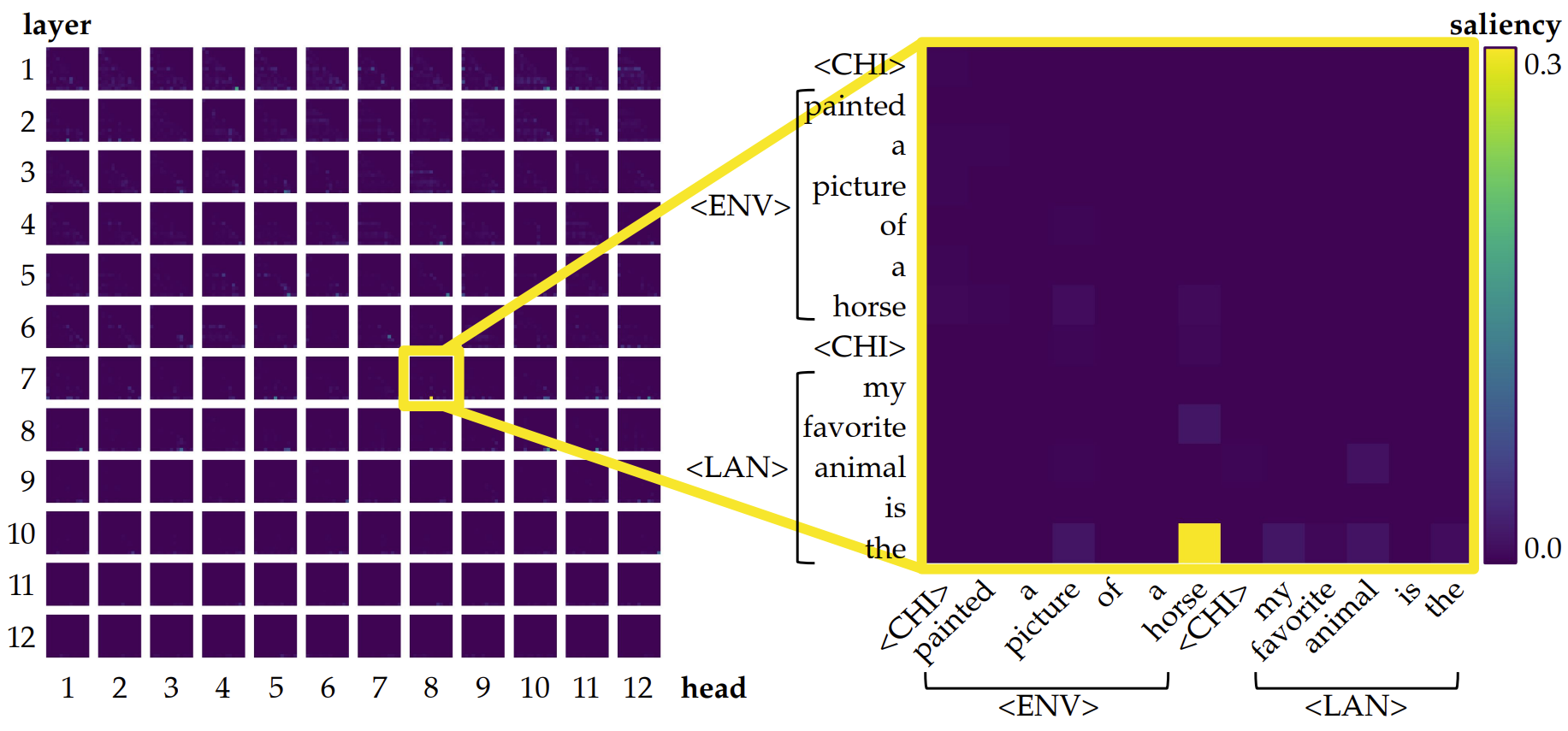
<ENV> to the current position, encouraging the model to predict horse<LAN> as the next token.
This is not surprising.
In our setup, the task structure itself makes gather heads unnecessary.
Because each target <LAN> token has a single corresponding
<ENV> token, the model can retrieve the needed information in a single hop
directly from the referent, which is precisely what aggregate heads are designed to do.
In contrast, gather heads become useful when there is an intermediate anchor token (such as
label words in few-shot ICL settings) that first collects information before being read by aggregate heads.
Since our format is semantically light and lacks these few-shot templates, no anchor emerges,
leaving the aggregate mechanism as the most efficient solution.
Realistic Settings
Now we extend experiments to more complicated settings with Visual Dialog dataset and Stable Diffusion 2 for image inpainting, as dipicted below:

<ENV>, shaded) with linguistic tokens (<LAN>). Test examples are constructed with either matched (book) or mismatched (toy) environmental contexts, paired with corresponding linguistic prompts. Note that in both child-directed speech and caption-grounded dialogue, book<ENV> and book<LAN> are two distinct tokens as received by the language model.For the VLM setting, we use DINOv2 as our ViT tokenizer because it is trained purely on vision data without any auxiliary text supervision. In contrast to models like CLIP, this ensures that environmental tokens capture only visual information, providing a cleaner and more controlled grounding signal. While standard LLaVA uses a two-layer perceptron to project ViT embeddings into the language model, we bypass this projection and directly feed the DINOv2 representations into the language model. This allows us to avoid introducing additional learned components and preserves the original visual signal more faithfully.
As shown above, the replication of behavioral findings is successful.
There is also an increase-the-decrease trend on the R2 metric,
which encourages us to directly test if the aggregate mechanism also plays a role here.
Before we moved on, we also repeated the experiment using a randomly initialized DINOv2 (see below). An advantage of the match condition over the mismatch condition was still observed, but it required significantly more training steps to approach convergence and did not fully converge even after 200K steps. While this is an interesting direction for further investigation, it is not central to our current research question, so we exclude this setting from the main analysis.
R2 ResultsSimilar to the previous text-only visualization, we plot the saliency of attention heads from each visual patch to the tested linguistic form.




Based on the above visualization, we identify attention heads as aggregate according to the following criterion (we do not define gather heads in this setting): an attention head is classified as an aggregate head if at least a certain threshold (70% or 90% in our experiments) of its total image patch-to-word saliency flows from patches inside the bounding box to the token immediately preceding the corresponding linguistic token.
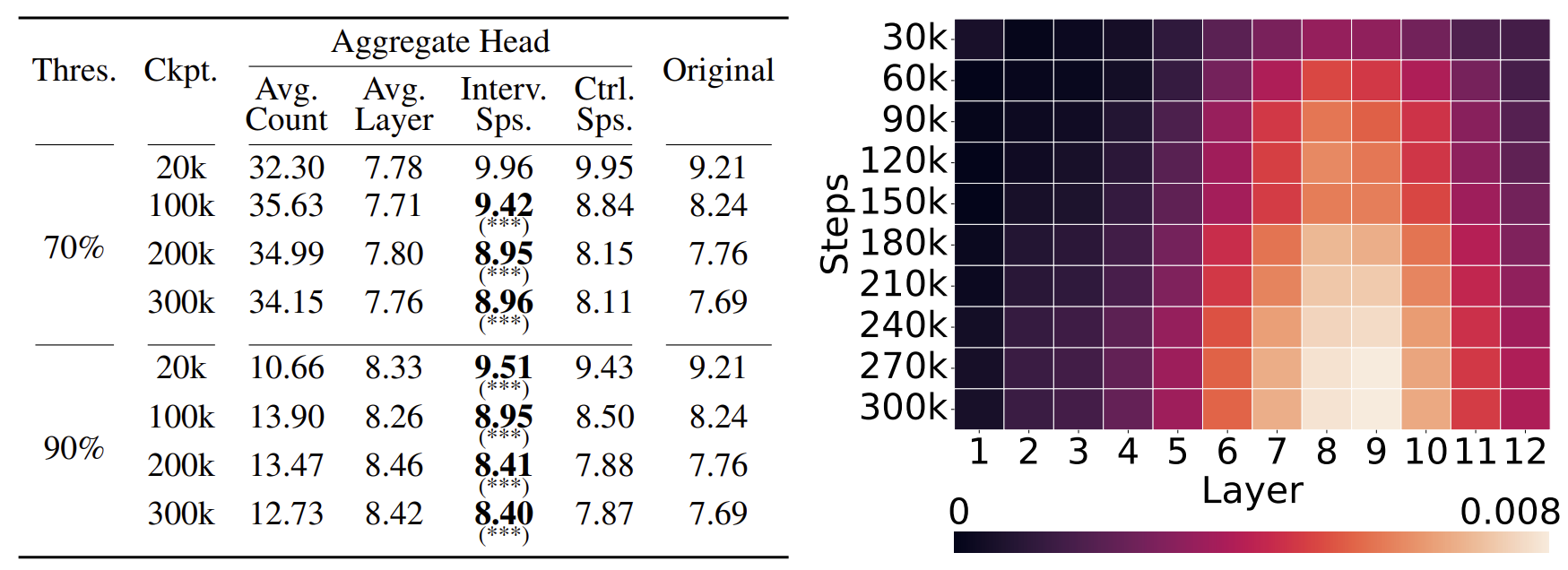
Consistently with what is shown in the minimum testbed setup, we find that aggregate heads are also the key to the performance in realistic vision-language models. Although early layers display little salient information flow (unlike in the minimal testbed), pronounced saliency in the middle layers remains a consistent and distinguishing feature.
We finally extend our grounding-as-aggregation hypothesis to a full-scale VLM (LLaVA-1.5-7B). Even in this heavily engineered architecture, we can easily identify attention heads that exhibit aggregation behavior consistent with our earlier findings. This reinforces our findings that symbol grounding arises from specialized heads, rather than being an artifact of statistics.
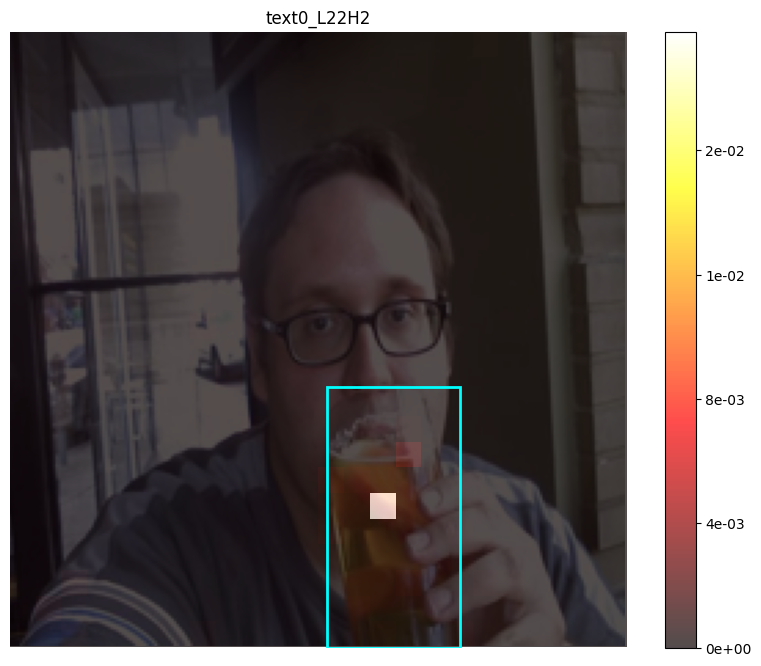

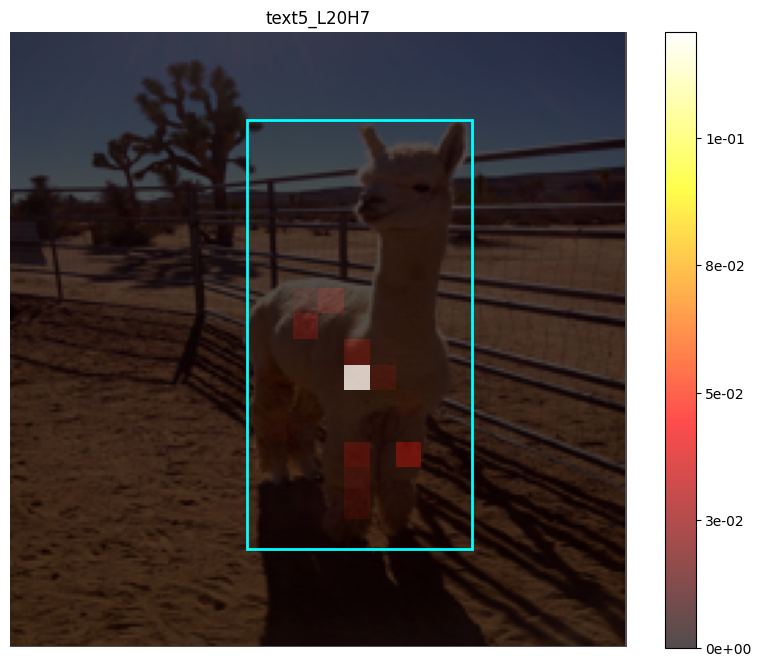

However, several challenges arise when we try to systematically identify and intervene on these heads at scale, just like what we did in prior sections.
- VLMs often incorporate multiple visual encoders (for example, LLaVA-1.5-HD), increasing architectural complexity.
- Many models rely on CLIP-derived embeddings that already encode language priors, making it difficult to treat the experiment as a controlled test of grounding emergence.
- The register token effect: global information may be stored in redundant artifact tokens rather than object-centric regions in the image.16 16 Vision Transformers Need Registers (Darcet et al., 2024)
- The large number of visual (environmental) tokens greatly increases computational cost and makes it difficult to define a universal criterion for identifying genuine aggregation heads, especially making fair comparisons across different VLMs.
We believe this is an important direction to pursue, but for now we have reached a natural stopping point. We have, so far, built a clean and formal testbed, presented reasonably realistic VLM setups, and provided case studies on full-scale models. Addressing the challenges discussed above will be essential for future work that aims to generalize our findings to more complex, real-world systems. However, we see this as a stand-alone project that goes beyond the scope of the current paper.
So we call it a day here.
Practical Implications
One might ask...does this mean we don't need grounding supervision to build mechanistically grounded VLMs? No. What our findings show is that grounding can emerge naturally from the training signal itself, but that does not make supervision unnecessary. Fine-grained mappings between text spans and semantic regions are well known to accelerate learning. While naturalistic data and minimal objectives alone can induce symbol grounding given sufficient scale and proper architecture, incorporating well-designed supervision or inductive biases can make models significantly more data-efficient, robust, and reliable, especially in low-resource settings.17,18 17 Grounded Language-Image Pre-training (Li*, Zhang*, and Zhang* et al., 2022) 18 World-to-Words: Grounded Open Vocabulary Acquisition through Fast Mapping in Vision-Language Models (Ma* and Pan* et al., 2023)
Our findings also imply a practical pathway to improving the reliability of language model outputs. By identifying aggregation heads that mediate grounding between environmental and linguistic tokens, we reveal an internal mechanism that can be monitored before generation occurs. This allows us to detect potential failure modes upstream rather than relying solely on output-level checks. 19 OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation (Huang et al., 2024)
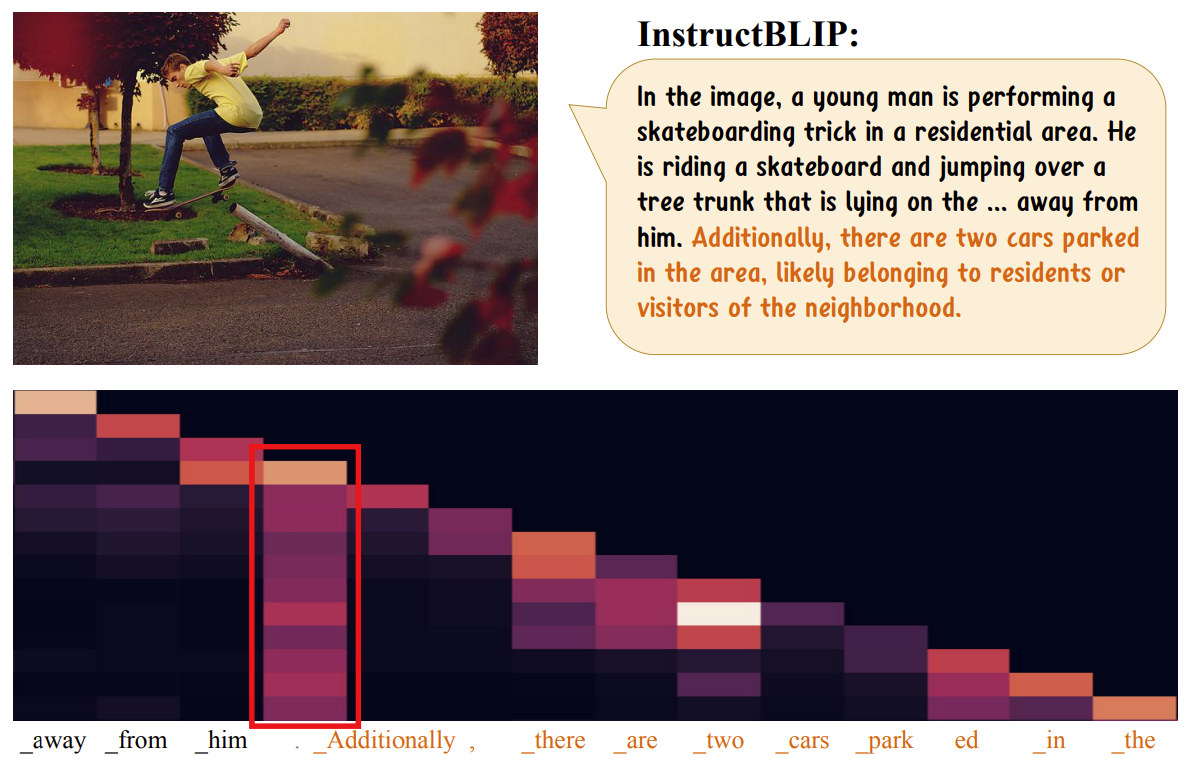
Many hallucination errors can be traced to misallocated attention in intermediate layers.20 20 Devils in Middle Layers of Large Vision-Language Models: Interpreting, Detecting and Mitigating Object Hallucinations via Attention Lens (Jiang et al., 2025) Because grounding is not uniformly distributed across the model, certain attention heads act as bottlenecks where environmental signals are either integrated correctly or distorted. Monitoring these heads provides a way to detect when the model is likely to produce unreliable outputs. Such attention-level signals offer a promising foundation for practical interventions. They can inform decoding-time strategies that adjust or constrain generation based on grounding strength, allowing for targeted mitigation and, ultimately, prevention of hallucinations.
Philosophical Implications
Our findings also highlight the need to sharpen what we mean by grounding in multimodal models. Much of the existing discourse has treated grounding as little more than statistical correlation between visual and linguistic signals. While such correlations are informative, they do not address the deeper question of whether symbols are causally anchored to their referents in the environment.
On another side of this debate, Gubelmann (2024)21 21 Pragmatic Norms Are All You Need - Why The Symbol Grounding Problem Does Not Apply to LLMs (Gubelmann, 2024) argues that the symbol grounding problem does not apply to large language models:
"LLMs, in contrast, are connectionist, statistical devices that have no intrinsic symbolic structure. It is, however, this symbolic structure that is presupposed in the CTM, the Chinese Room Thought Experiment, and hence also in the symbol grounding problem."
Our results suggest otherwise. We observe emergent symbolic structure as a mechanistic property of the model: it can be traced along the training trajectory, localized to specific attention heads, and tested through causal interventions.
We echo Pavlick (2023)22 22 Symbols and grounding in large language models (Pavlick, 2023) that "LLMs lack the capacity to represent abstract symbolic structure" should not be accepted a priori. Instead, these claims must be empirically tested, with the focus placed on uncovering the models' underlying competence rather than relying solely on surface-level performance.
This perspective shifts the debate from abstract philosophical claims to testable mechanisms. Grounding can be investigated as a measurable process within models, rather than simply dismissed as irrelevant by definition. More importantly, it provides a practical diagnostic pathway for identifying when and how models begin to tie symbols to meaning, moving the discussion beyond surface correlations toward mechanistic explanations with the power of computation.
Citation
To give credit if you find this work useful, please cite:
@article{wu2025mechanistic,
title={The Mechanistic Emergence of Symbol Grounding in Language Models},
author={Wu, Shuyu and Ma, Ziqiao and Luo, Xiaoxi and Huang, Yidong and Torres-Fonseca, Josue and Shi, Freda and Chai, Joyce},
journal={arXiv preprint arXiv:2510.13796},
year={2025}
}